先占坑,稍候回来完成
前几天通过掘金投了心知科技的简历,今天收到了电话。
晚些时候约好了和心知科技的长得挺帅的小哥“聊了聊”,
小哥问了我一个这样的问题,当时也没好好分析,下面我总结一下。
三门问题
参赛者会看见三扇关闭了的门,其中一扇的后面有一辆汽车,选中后面有车的那扇门可赢得该汽车,另外两扇门后面则各藏有一只山羊。当参赛者选定了一扇门,但未去开启它的时候,节目主持人开启剩下两扇门的其中一扇,露出其中一只山羊。主持人其后会问参赛者要不要换另一扇仍然关上的门。问题是:换另一扇门会否增加参赛者赢得汽车的机率?
我的解法
要是直接按照概率论讲明也太麻烦了,所以,我们来测试它几千万次,看看结果呗。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44//换了的正确次数
let resultChange = 0;
//不换正确的次数
let resultUnChange = 0;
//所有正确的结果
let randomList = {};
let doorSize = 3;
for(let i=0;i<10000000;i++){
let randomPrise = Math.floor(Math.random()*doorSize); //真正奖品存在的门
let randomSelect = Math.floor(Math.random()*doorSize);//你第一次选的门
let removeSelect = null;//主持人帮我排除掉的选项
if(randomPrise in randomList){
randomList[randomPrise]++;
}else{
randomList[randomPrise] = 1;
}
/**
* 帮我排除一个选项,
* 如果这个选项是我选的,则不排除
* 如果这个选项不是选的,但是是奖品,不排除
*/
for(let j=0;j<doorSize;j++){
if(j===randomSelect){
continue;
}
if(j===randomPrise){
continue;
}
removeSelect = j;
}
//换了正确
if(randomPrise!==randomSelect&&randomPrise!==removeSelect){
resultChange++;
}
//不换正确
if(randomSelect===randomPrise){
resultUnChange++;
}
}
console.log(randomList);
console.log('换了的正确率',resultChange/10000000);
console.log('不换的正确率',resultUnChange/10000000);
结果如下:1
2
3{ '0': 3333844, '1': 3334541, '2': 3331615 }
换了的正确率 0.6666581
不换的正确率 0.3333419
很容易看出来啊,当然换了好。
从概率论方面解读
首先,汽车放到哪个门后如果用一个数组可以表示成这样,[0,1,0]
那么可能的结果会是:
[1,0,0] [0,1,0] [0,0,1]
这三种,其实我们第一次选择哪个都不影响最终的概率,所以,我们就假设:
我们第一次选的数组的第一个元素,那么我们分析一下:
| 选项 | 主持人去掉一个后的结果 | 换能拿到汽车 |
|---|---|---|
[1,0,0] |
[1,0] |
× |
[0,1,0] |
[0,1] |
√ |
[0,0,1] |
[0,1] |
√ |
很明显,换的概率是 66.67% ,不换 33.33%。

背景
在开发Reversi_process
( 用Node.js 将黑白棋对局的每一步保存成本地图片的)的时候,遇到这样的需求:
先在 Node-Canvas 画出每一步的图片,然后保存下来。
在绘制下一张图片的时候,要保证前一张图片被保存下来。不然保存的图片可能会乱。
但是如果用同步的方法保存,整个过程下来是相当的费时。
生成一个有60步的对局大约需要 12000ms 。于是有了下面这个解决办法。
环境
- Node.js: v7.9.0
- node-canvas: 1.6.5
阅读前需要对 Promise 和 async/await 有一定了解
异步进行 Canvas 保存成图片
首先,将异步 fs.writeFile 封装成一个 Promise 方法。
1 | /** |
之后,我们用一个数组来存每一步的 Promise 对象,在保存每一步 Canvas 图像的时候
我们创建一个当前 Canvas 的副本。如果直接传入当前 Canvas 的时候,会导致保存后的图片乱掉。
在这里我们使用了 toDataURL() 的异步使用方法
1 | canvas.toDataURL('image/png', function(err, png){ }); |
因为 toDataURL() 将非常耗时,在本例中,平均保存一步对局需要 600ms
在 toDataURL() 回调中,我们调用上面封装成 Promise 方法的 saveImg(name, dataBuffer)
方法,并将返回的 Promise 对象添加到 promises 数组中。
之后我们只要保证 promises 中的 Promise 全部执行完成就可以了。
只要调用 Promise.all( iterable ); 将 promises 传入即可,等待 promises 方法全部执行完后
返回一个新的 Promise 对象,处理之后便可以进行之后的工作了。
代码如下(使用了 async/await 新特性,NodeJs v7.4.0 后正式加入)
1 | DrawChessboard.prototype.draw = async function (/*string*/chessString) { |
fs(文件系统)
通过 require(‘fs’) 使用该模块。 所有的方法都有异步和同步的形式。
异步版本:1
2
3
4
5
6const fs = require('fs');
fs.unlink('/tmp/hello', (err) => {
if (err) throw err;
console.log('successfully deleted /tmp/hello');
});
同步版本:1
2
3
4const fs = require('fs');
fs.unlinkSync('/tmp/hello');
console.log('successfully deleted /tmp/hello');
基本方法
readFile1
2
3
4
5
6
7fs.readFile(file[, options], callback)
file <String> | <Buffer> | <Integer> 文件名或文件描述符
options <Object> | <String>
encoding <String> | <Null> 默认 = null
flag <String> 默认 = 'r'
callback <Function>
1 | fs.readFile('/etc/passwd', (err, data) => { |
writeFile1
2
3
4
5
6
7
8fs.writeFile(file, data\[, options], callback)
file <String> | <Buffer> | <Integer> 文件名或文件描述符
data <String> | <Buffer>
options <Object> | <String>
encoding <String> | <Null> 默认 = 'utf8'
mode <Integer> 默认 = 0o666
flag <String> 默认 = 'w'
callback <Function>
1 | fs.writeFile('message.txt', 'Hello Node.js', (err) => { |
注意点
不建议在调用 fs.open() 、 fs.readFile() 或 fs.writeFile()
之前使用 fs.access() 检查一个文件的可访问性。 如此处理会造成紊乱情况,
因为其他进程可能在两个调用之间改变该文件的状态。 作为替代,
用户代码应该直接打开/读取/写入文件,当文件无法访问时再处理错误。
终极异步方案
JavaScript异步编程一直是一件很麻烦的事,从最早的回调函数,到 Promise 对象,
再到 Generator 函数,每次都有所改进。但总感觉缺点什么。
直到 async/await 出现,很多人认为它是异步操作的终极解决方案。
async 应该会在 ECMAScript 7 引入。在 NodeJs v7.4.0 正式加入 NodeJs 大家庭。
async 是 Generator 函数的语法糖
1 | var fs = require('fs'); |
Generator 写法:1
2
3
4
5
6
7
8var co = require('co');
var gen = function* (){
var f1 = yield readFile('/etc/fstab');
var f2 = yield readFile('/etc/shells');
console.log(f1.toString());
console.log(f2.toString());
};
co(gen);
写成 async 函数,就像下面这样:1
2
3
4
5
6var asyncReadFile = async function (){
var f1 = await readFile('/etc/fstab');
var f2 = await readFile('/etc/shells');
console.log(f1.toString());
console.log(f2.toString());
};
其实就是把 * 替换成 async ,把 yield 换成 await。而且自带执行器
(Generator 函数的执行必须依靠执行器,所以才有了 co 函数库)。
async 函数用法
同 Generator 函数一样,async 函数返回一个 Promise 对象。
所以调用 async 函数的函数也要处理 Promise 对象。用 try…catch 来处理 Promise 对象 rejected
await 命令只能用在 async 函数之中,如果用在普通函数,就会报错。
将 forEach 方法的参数改成 async 函数不能够实现继发执行。应该采用 for 循环。
希望多个请求并发执行,可以使用 Promise.all 方法。
CommonJS
首先,最先出现的是 CommonJS, CommonJS API 定义很多普通应用程序(主要指非浏览器的应用)使用的API。它的终极目标是提供一个类似 Python, Ruby 和 Java 标准库。这样的话,开发者可以使用 CommonJS API 编写应用程序,然后这些应用可以运行在不同的 JavaScript 解释器和不同的主机环境中。
2009年,美国程序员 Ryan Dahl 创造了 node.js 项目,将 javascript 语言用于服务器端编程。这标志 Javascript 模块化编程”正式诞生。
NodeJS 是 CommonJS 规范的实现, webpack 也是以 CommonJS 的形式来书写。NPM 作为 Node 的包管理器,帮助Node 解决依赖包的安装问题,也要遵循 CommonJS。
Browserify
browserify 是最常用的 CommonJS 转换工具。
然后看个例子1
2
3
4
5
6
7
8// foo.js
module.exports = function(x) {
console.log(x);
};
// main.js
var foo = require("./foo");
foo("Hi");
1 | $ browserify main.js > compiled.js |
即可打包,Browserify 具体做了什么继续向下看即可:1
$ npm install browser-unpack -g
然后我们将上面生成的 compiled.js 解包。
1 | $ browser-unpack < compiled.js |
Browserify 在这里将所有模块放到一个数组里,id 是模块的编号,source 是源码,deps 为依赖,entry 为指定入口。
Browserify 先找到 entry: true 的地方,然后执行 source 中的代码,遇到 require 就去deps 中寻找依赖,并执行所依赖的代码,将结果赋值给 require 前的变量。
AMD
AMD ( Asynchronous Module Definition ),是为了解决 CommonJS 不能异步加载的问题。AMD 采用异步的方式加载模块,模块的加载不影响它后面语句的运行。所有依赖这个模块的语句,都定义在一个回调函数中,等加载完成后,这个回调函数才会执行。
AMD 也采用 require() 语句加载模块,但是不同于 CommonJS,它要求两个参数:1
require([module], callback);
第一个参数 [module] ,是一个数组,里面的成员就是要加载的模块;第二个参数 callback ,则是加载成功之后的回调函数。如果将前面的代码改写成 AMD 形式,就是下面这样:
1 | require(['math'], function (math) { |
math.add() 与 math 模块加载不是同步的,浏览器不会发生假死。所以很显然,AMD 比较适合浏览器环境。目前,主要有两个 Javascript 库实现了 AMD 规范: require.js 和 curl.js。
require.js
先去官方网站下载最新版本。
1 | 然后将它放到项目中即可 |
如果加载这个文件,也可能造成网页失去响应。解决办法有两个,一个是把它放在网页底部加载,另一个是写成下面这样:1
<script src="js/require.js" defer async="true" ></script>
async 属性表明这个文件需要异步加载,避免网页失去响应。IE不支持这个属性,只支持 defer,所以把 defer 也写上。
加载 require.js 以后,下一步就要加载我们自己的代码了。假定我们自己的代码文件是 main.js ,也放在 js 目录下面。那么,只需要写成下面这样就行了:
1 | <script src="js/require.js" data-main="js/main"></script> |
data-main 属性的作用是,指定网页程序的主模块。在上例中,就是js目录下面的 main.js ,这个文件会第一个被 require.js加载。由于 require.js 默认的文件后缀名是js,所以可以把 main.js 简写成 main。
主模块的写法:1
2
3
4// main.js
require(['moduleA', 'moduleB', 'moduleC'], function (moduleA, moduleB, moduleC){
// some code here
});
默认情况下,require.js 假定这三个模块与 main.js 在同一个目录,文件名分别为 moduleA.js,moduleB.js 和 moduleA.js,然后自动加载。
使用 require.config() 方法,我们可以对模块的加载行为进行自定义。require.config() 就写在主模块(main.js)的头部。参数就是一个对象,这个对象的 paths 属性指定各个模块的加载路径。
1 | require.config({ |
模块的写法
模块必须采用特定的 define() 函数来定义。如果一个模块不依赖其他模块,那么可以直接定义在 define() 函数之中。
1 | // math.js |
ES6 module
ES6发布的 module 并没有直接采用 CommonJS ,甚至连 require 都没有采用,也就是说 require 仍然只是 node 的一个私有的全局方法,module.exports 也只是 node 私有的一个全局变量属性,跟标准半毛钱关系都没有。
区别
require 的使用非常简单,它相当于 module.exports 的传送门,module.exports 后面的内容是什么,require 的结果就是什么,对象、数字、字符串、函数……再把 require 的结果赋值给某个变量,相当于把 require 和 module.exports 进行平行空间的位置重叠,而且 require 理论上可以运用在代码的任何地方,甚至不需要赋值给某个变量之后再使用。在使用时,完全可以忽略模块化这个概念来使用 require,仅仅把它当做一个 node 内置的全局函数,它的参数甚至可以是表达式:
但是 import 则不同,它是编译时的(require是运行时的),它必须放在文件开头,而且使用格式也是确定的,不容置疑。它不会将整个模块运行后赋值给某个变量,而是只选择 import 的接口进行编译,这样在性能上比 require 好很多。
从理解上,require 是赋值过程,import 是解构过程,当然,require 也可以将结果解构赋值给一组变量,但是 import 在遇到 default 时,和 require 则完全不同: var $ = require('jquery'); 和 import $ from 'jquery' 是完全不同的两种概念。
初始化邮箱用户名
1 | git config --global user.email "shianqi@imudges.com" |
1 | git config --global user.name "shianqi" |
生成SSH密钥
1 | ssh-keygen -t rsa -C "shianqi@imudges.com" |
windows 需要在 GitBush 中添加
将密钥添加到 Github 设置中
测试连接
1 | ssh -T git@github.com |
出现下面的文本,则链接成功1
Hi shianqi! You've successfully authenticated, but GitHub does not provide shell access.
注意: 正则表达式中不要插入没用的空格。
直接量字符
| 字符 | 匹配 |
|---|---|
| 字母和数字字符 | 自身 |
| \o | NUL字符 (\u0000) |
| \t | 制表符 (\u0009) |
| \n | 换行符 (\u000A) |
| \v | 垂直制表符 (\u000B) |
| \f | 换页符 (\u000C) |
| \r | 回车符 (\u000D) |
字符类
| 字符 | 匹配 |
|---|---|
| […] | 方括号内的任意字符 |
| [^…] | 不在方括号内的任意字符 |
| . | 除换行符和其他Unicode行终止符之外的任意字符 |
| \w | 任何ASCII字符组成的单词,等价于[a-zA-Z0-9] |
| \W | 任何不是ASCII字符组成的单词,等价于[^a-zA-Z0-9] |
| \s | 任何Unicode空白符 |
| \S | 任何非Unicode空白符的字符,和\w和\S不同 |
| \d | 任何ASCII数字,等价于[0-9] |
| \D | 除了ASCII数字之外的任何字符,等价于[^0-9] |
| [\b] | 退格直接量 |
重复
| 字符 | 含义 |
|---|---|
| {n,m} | 匹配前一项至少n次,但是不能超过m次 |
| {n,} | 匹配前一项n次或者更多次 |
| {n} | 匹配前一项n次 |
| ? | 匹配前一项0次或1次, 等价于 { 0, 1 } |
| + | 匹配前一项1次或多次,等价于 { 1, } |
| * | 匹配前一项0次或多次,等价于 { 0, } |
非贪婪的重复: 例如“??”,“+?”,“*?”
正则表达式的选择,分组和引用字符
| 字符 | 含义 |
|---|---|
| | | 选择,匹配的是该符号左边的子表达式或右边的子表达式 |
| (…) | 组合,将几个项组合为一个单元,这个单元可通过 “ * ”,“ + ”,“ ? ” 和 “ | ” 等符号修饰,而且可以记住和这个组合相匹配的字符串供引用使用 |
| (?:…) | 只组合,把项目组合到一个单元,但不记忆与该组相匹配的字符 |
| \n | 和第 n 个富足第一次匹配的字符相匹配,组是圆括号中的子表达式,组索引是从左到右的左括号数 |
锚字符
| 字符 | 含义 |
|---|---|
| \^ | 匹配字符串的开头,在多行检索中,匹配一行开头 |
| \& | 匹配字符串的结尾,在多行检索中,匹配一行结尾 |
| \b | 匹配字符串的边界,位于字符\w和\W之间的位置 |
| \B | 匹配非单词边界的位置 |
| (?=p) | 零宽正向先行断言,要求接下来的字符都与p匹配,但不能包括匹配p的那些字符 |
| (?!p) | 零宽负向先行断言,要求接下来的字符都不与p匹配 |
修饰符
| 字符 | 含义 |
|---|---|
| i | 执行不区分大小写的匹配 |
| g | 执行一个全局匹配,找到所有的匹配,而不是在找到一个就停止 |
| m | 多行匹配模式 |
用于匹配的String方法
search() 返回匹配字符串的起始坐标,没有则返回-1
replace() 两个参数,替换字符
match() 匹配字符串如果没有修饰符g,则不进行全局检索,返回一个数组,在其中可以用括号匹配详细内容
1 | let result = 'visit my Blog :https://www.baidu.com:80'.match(/(https?):\/\/([\w.]+):(\d*)/); |
结果
1 | [ 'https://www.baidu.com:80', |
split() 截取字符串
CSS3 flex 布局
- container 属性
- flex-direction ———/ 主轴方向 /
- flex-wrap ————–/ 主轴不能容纳如何换行 /
- flex-flow ————–/ 缩写
|| / - justify-content———/ Item 在主轴上的排列方式 /
- align-items————-/ 项目在主轴上如何对齐 /
- align-content———–/ 多根交叉轴线的对齐方式/
- item 属性
- order——————-/ 项目排列顺序,值小靠前 /
- flex-grow—————/ item 有剩余空间缩放比例,默认为0,不缩放 /
- flex-shrink————-/ item 空间不足时缩小比例,默认为1,该项目将缩小。 /
- flex-basis————–/ 在分配多余空间之前,项目占据的主轴空间 /
- flex——————–/ 前三项的缩写,默认为 0 1 auto /
- align-self————–/ 允许单个项目有与其他项目不一样的对齐方式 覆盖align-items /
Flex 是Flexible Box的缩写,意为”弹性布局“,
用来为盒状模型提供最大的灵活性。
任何一个容器都可以指定为Flex布局。1
2
3.box{
display: flex;
}
行内元素:1
2
3.box{
display: inline-flex;
}
Webkit内核的浏览器,必须加上-webkit前缀。
1 | .box{ |
注意:设为Flex布局以后,子元素的
float、
clear 和
vertical-align
属性将失效。
概念
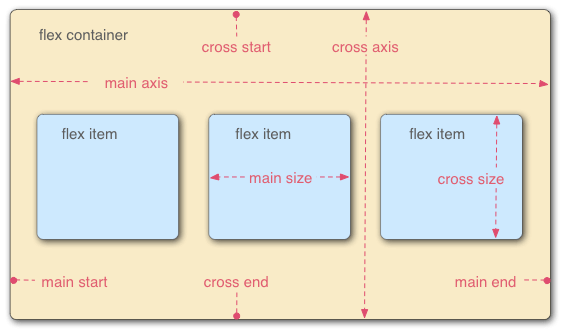
container 属性
flex-direction
决定主轴的方向 ( 项目的排列方向 )
1 | row(默认值): //主轴为水平方向,起点在左端。 |
flex-wrap
主轴不能容纳如何换行
1 | nowrap(默认值): //不换行。 |
flex-flow
flex-direction 属性和 flex-wrap 属性 的简写形式
justify-content
项目在主轴上的对齐方式
1 | flex-start(默认值): //左对齐 |
align-items
项目在交叉轴上如何对齐
1 | flex-start: //交叉轴的起点对齐。 |
align-content
多根轴线的对齐方式,只有一根轴不起作用
1 | flex-start: //与交叉轴的起点对齐。 |
item 属性
order
项目的排列顺序。数值越小,排列越靠前,默认为0。
flex-grow
项目的放大比例,默认为0,即如果存在剩余空间,也不放大。
flex-shrink
项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。
flex-basis
在分配多余空间之前,项目占据的主轴空间
flex
flex-grow, flex-shrink 和 flex-basis
的简写,默认值为0 1 auto。后两个属性可选。
align-self
属性允许单个项目有与其他项目不一样的对齐方式
可覆盖align-items属性。默认值为auto,表示继承父元素的align-items属性,
如果没有父元素,则等同于stretch。
1 | flex-start: //交叉轴的起点对齐。 |
文章参考:原文链接
客户服务器方式与对等通信方式的主要区别是什么?有没有相同的地方?
前者严格区分服务和被服务者,后者无此区别。后者实际上是前者的双向应用。
论述具有五层协议的网络体系结构的要点,包括各层的主要功能。
答:综合OSI 和TCP/IP 的优点,采用一种原理体系结构。各层的主要功能:
- 物理层 物理层的任务就是透明地传送比特流。(注意:传递信息的物理媒体,如双绞线、同轴电缆、光缆等,是在物理层的下面,当做第0 层。) 物理层还要确定连接电缆插头的定义及连接法。
- 数据链路层 数据链路层的任务是在两个相邻结点间的线路上无差错地传送以帧(frame)为单位的数据。每一帧包括数据和必要的控制信息。
- 网络层 网络层的任务就是要选择合适的路由,使 发送站的运输层所传下来的分组能够正确无误地按照地址找到目的站,并交付给目的站的运输层。
- 运输层 运输层的任务是向上一层的进行通信的两个进程之间提供一个可靠的端到端服务,使它们看不见运输层以下的数据通信的细节。
- 应用层 应用层直接为用户的应用进程提供服务。
数据链路层的三个基本问题(封装成帧、透明传输和差错检测)为什么都必须加以解决?
答:
封装成帧 是分组交换的必然要求
透明传输 避免消息符号与帧定界符号相混淆
差错检测 防止合差错的无效数据帧浪费后续路由上的传输和处理资源
要发送的数据为1101011011。采用CRC的生成多项式是P(X)=X4+X+1。试求应添加在数据后面的余数。数据在传输过程中最后一个1变成了0,问接收端能否发现?若数据在传输过程中最后两个1都变成了0,问接收端能否发现?采用CRC检验后,数据链路层的传输是否就变成了可靠的传输?
答:作二进制除法,1101011011 0000 10011 得余数1110 ,添加的检验序列是1110.作二进制除法,两种错误均可发展仅仅采用了CRC检验,缺重传机制,数据链路层的传输还不是可靠的传输。
一个PPP帧的数据部分(用十六进制写出)是7D 5E FE 27 7D 5D 7D 5D 65 7D 5E。试问真正的数据是什么(用十六进制写出)?
答:7D 5E FE 27 7D 5D 7D 5D 65 7D 5E
7E FE 27 7D 7D 65 7E1
7D 5E->7E
假定1km长的CSMA/CD网络的数据率为1Gb/s。设信号在网络上的传播速率为200000km/s。求能够使用此协议的最短帧长。
答:对于1km电缆,单程传播时间为1/200000=5为微秒,来回路程传播时间为10微秒,为了能够按照CSMA/CD工作,最小帧的发射时间不能小于10微秒,以Gb/s速率工作,10微秒可以发送的比特数等于1010^-6/110^-9=10000,因此,最短帧是10000位或1250字节长
假定在使用CSMA/CD协议的10Mb/s以太网中某个站在发送数据时检测到碰撞,执行退避算法时选择了随机数r=100。试问这个站需要等待多长时间后才能再次发送数据?如果是100Mb/s的以太网呢?
答:对于10mb/s的以太网,以太网把争用期定为51.2微秒,要退后100个争用期,等待时间是51.2(微秒)100=5.12ms
对于100mb/s的以太网,以太网把争用期定为5.12微秒,要退后100个争用期,等待时间是5.12(微秒)100=512微秒
试说明IP地址与硬件地址的区别,为什么要使用这两种不同的地址?
IP 地址就是给每个连接在因特网上的主机(或路由器)分配一个在全世界范围是唯一的 32 位的标识符。从而把整个因特网看成为一个单一的、抽象的网络
在实际网络的链路上传送数据帧时,最终还是必须使用硬件地址。
MAC地址在一定程度上与硬件一致,基于物理、能够标识具体的链路通信对象、IP地址给予逻辑域的划分、不受硬件限制。
(1)子网掩码为255.255.255.0代表什么意思?
有三种含义
其一是一个A类网的子网掩码,对于A类网络的IP地址,前8位表示网络号,后24位表示主机号,使用子网掩码255.255.255.0表示前8位为网络号,中间16位用于子网段的划分,最后8位为主机号。
第二种情况为一个B类网,对于B类网络的IP地址,前16位表示网络号,后16位表示主机号,使用子网掩码255.255.255.0表示前16位为网络号,中间8位用于子网段的划分,最后8位为主机号。
第三种情况为一个C类网,这个子网掩码为C类网的默认子网掩码。
(2)一网络的现在掩码为255.255.255.248,问该网络能够连接多少个主机?
255.255.255.248即11111111.11111111.11111111.11111000.
每一个子网上的主机为(2^3)=6 台
掩码位数29,该网络能够连接8个主机,扣除全1和全0后为6台。
(3)一A类网络和一B网络的子网号subnet-id分别为16个1和8个1,问这两个子网掩码有何不同?
A类网络:11111111 11111111 11111111 00000000
给定子网号(16位“1”)则子网掩码为255.255.255.0
B类网络 11111111 11111111 11111111 00000000
给定子网号(8位“1”)则子网掩码为255.255.255.0但子网数目不同
(4)一个B类地址的子网掩码是255.255.240.0。试问在其中每一个子网上的主机数最多是多少?
(240)10=(128+64+32+16)10=(11110000)2
Host-id的位数为4+8=12,因此,最大主机数为:
2^12-2=4096-2=4094
11111111.11111111.11110000.00000000 主机数2^12-2
(5)一A类网络的子网掩码为255.255.0.255;它是否为一个有效的子网掩码?
是 10111111 11111111 00000000 11111111
(6)某个IP地址的十六进制表示C2.2F.14.81,试将其转化为点分十进制的形式。这个地址是哪一类IP地址?
C2 2F 14 81–à(1216+2).(216+15).(16+4).(8*16+1)—à194.47.20.129
C2 2F 14 81 —à11000010.00101111.00010100.10000001
C类地址
(7)C类网络使用子网掩码有无实际意义?为什么?
有实际意义.C类子网IP地址的32位中,前24位用于确定网络号,后8位用于确定主机号.如果划分子网,可以选择后8位中的高位,这样做可以进一步划分网络,并且不增加路由表的内容,但是代价是主机数相信减少.
10.试辨认以下IP地址的网络类别。
(1)128.36.199.3
(2)21.12.240.17
(3)183.194.76.253
(4)192.12.69.248
(5)89.3.0.1
(6)200.3.6.2
(2)和(5)是A类,(1)和(3)是B类,(4)和(6)是C类.
当某个路由器发现一IP数据报的检验和有差错时,为什么采取丢弃的办法而不是要求源站重传此数据报?计算首部检验和为什么不采用CRC检验码?
答:纠错控制由上层(传输层)执行
IP首部中的源站地址也可能出错请错误的源地址重传数据报是没有意义的
不采用CRC简化解码计算量,提高路由器的吞吐量
设某路由器建立了如下路由表:
目的网络 子网掩码 下一跳
128.96.39.0 255.255.255.128 接口m0
128.96.39.128 255.255.255.128 接口m1
128.96.40.0 255.255.255.128 R2
192.4.153.0 255.255.255.192 R3
*(默认) —— R4
现共收到5个分组,其目的地址分别为:
(1)128.96.39.10
(2)128.96.40.12
(3)128.96.40.151
(4)192.153.17
(5)192.4.153.90
#####(1)分组的目的站IP地址为:128.96.39.10。先与子网掩码255.255.255.128相与,得128.96.39.0,可见该分组经接口0转发。
#####(2)分组的目的IP地址为:128.96.40.12。
① 与子网掩码255.255.255.128相与得128.96.40.0,不等于128.96.39.0。
② 与子网掩码255.255.255.128相与得128.96.40.0,经查路由表可知,该项分组经R2转发。
#####(3)分组的目的IP地址为:128.96.40.151,与子网掩码255.255.255.128相与后得128.96.40.128,与子网掩码255.255.255.192相与后得128.96.40.128,经查路由表知,该分组转发选择默认路由,经R4转发。
#####(4)分组的目的IP地址为:192.4.153.17。与子网掩码255.255.255.128相与后得192.4.153.0。与子网掩码255.255.255.192相与后得192.4.153.0,经查路由表知,该分组经R3转发。
#####(5)分组的目的IP地址为:192.4.153.90,与子网掩码255.255.255.128相与后得192.4.153.0。与子网掩码255.255.255.192相与后得192.4.153.64,经查路由表知,该分组转发选择默认路由,经R4转发。
一个大公司有一个总部和三个下属部门。公司分配到的网络前缀是192.77.33/24.公司的网络布局如图4-56示。总部共有五个局域网,其中的LAN1-LAN4都连接到路由器R1上,R1再通过LAN5与路由器R5相连。R5和远地的三个部门的局域网LAN6~LAN8通过广域网相连。每一个局域网旁边标明的数字是局域网上的主机数。试给每一个局域网分配一个合适的网络的前缀。
(P380)
已知地址块中的一个地址是140.120.84.24/20。试求这个地址块中的最小地址和最大地址。地址掩码是什么?地址块中共有多少个地址?相当于多少个C类地址?
140.120.84.24 è 140.120.(0101 0100).24
最小地址是 140.120.(0101 0000).0/20 (80)
最大地址是 140.120.(0101 1111).255/20 (95)
地址数是4096.相当于16个C类地址。
假定网络中的路由器B的路由表有如下的项目(这三列分别表示“目的网络”、“距离”和“下一跳路由器”)
N1 7 A
N2 2 B
N6 8 F
N8 4 E
N9 4 F
现在B收到从C发来的路由信息(这两列分别表示“目的网络”“距离”):
N2 4
N3 8
N6 4
N8 3
N9 5
试求出路由器B更新后的路由表(详细说明每一个步骤)。
路由器B更新后的路由表如下:
N1 7 A 无新信息,不改变
N2 5 C 相同的下一跳,更新
N3 9 C 新的项目,添加进来
N6 5 C 不同的下一跳,距离更短,更新
N8 4 E 不同的下一跳,距离一样,不改变
N9 4 F 不同的下一跳,距离更大,不改变

