面试知识点汇总
- 以太网 MAC 地址的长度是 48位
- 在Unix系统中进程由三部分组成,分别是进程控制块、正文段和数据段。Unix系统中把进程控制块分成proc结构和user结构两部分
proc存放的是系统经常要查询和修改的信息,需要快速访问,因此常将其装入内存 - 段页式存储管理, 段内 、 页面 地址是连续的,这种连续地址采用 一 维地址空间
- 现代操作系统的基本特征是 程序的并发执行
- 在Java中 数组是一种对象
用更合理的方式写 JavaScript
原始值: 存取直接作用于它自身。
stringnumberbooleannullundefined1 | var foo = 1; |
复杂类型: 存取时作用于它自身值的引用。
objectarrayfunction1 | var foo = [1, 2]; |
使用直接量创建对象。
1 | // bad |
不要使用保留字作为键名,它们在 IE8 下不工作。更多信息。
1 | // bad |
使用同义词替换需要使用的保留字。
1 | // bad |
使用直接量创建数组。
1 | // bad |
向数组增加元素时使用 Array#push 来替代直接赋值。
1 | var someStack = []; |
当你需要拷贝数组时,使用 Array#slice。jsPerf
1 | var len = items.length; |
使用 Array#slice 将类数组对象转换成数组。
1 | function trigger() { |
使用单引号 '' 包裹字符串。
1 | // bad |
超过 100 个字符的字符串应该使用连接符写成多行。
注:若过度使用,通过连接符连接的长字符串可能会影响性能。jsPerf & 讨论.
1 | // bad |
程序化生成的字符串使用 Array#join 连接而不是使用连接符。尤其是 IE 下:jsPerf.
1 | var items; |
函数表达式:
1 | // 匿名函数表达式 |
永远不要在一个非函数代码块(if、while 等)中声明一个函数,把那个函数赋给一个变量。浏览器允许你这么做,但它们的解析表现不一致。
注: ECMA-262 把 块 定义为一组语句。函数声明不是语句。阅读对 ECMA-262 这个问题的说明。
1 | // bad |
永远不要把参数命名为 arguments。这将取代函数作用域内的 arguments 对象。
1 | // bad |
使用 . 来访问对象的属性。
1 | var luke = { |
当通过变量访问属性时使用中括号 []。
1 | var luke = { |
总是使用 var 来声明变量。不这么做将导致产生全局变量。我们要避免污染全局命名空间。
1 | // bad |
使用 var 声明每一个变量。
这样做的好处是增加新变量将变的更加容易,而且你永远不用再担心调换错 ; 跟 ,。
1 | // bad |
最后再声明未赋值的变量。当你需要引用前面的变量赋值时这将变的很有用。
1 | // bad |
在作用域顶部声明变量。这将帮你避免变量声明提升相关的问题。
1 | // bad |
变量声明会提升至作用域顶部,但赋值不会。
1 | // 我们知道这样不能正常工作(假设这里没有名为 notDefined 的全局变量) |
匿名函数表达式会提升它们的变量名,但不会提升函数的赋值。
1 | function example() { |
命名函数表达式会提升变量名,但不会提升函数名或函数体。
1 | function example() { |
函数声明提升它们的名字和函数体。
1 | function example() { |
了解更多信息在 JavaScript Scoping & Hoisting by Ben Cherry.
=== 和 !== 而不是 == 和 !=.条件表达式例如 if 语句通过抽象方法 ToBoolean 强制计算它们的表达式并且总是遵守下面的规则:
'' 被计算为 false,否则为 true1 | if ([0]) { |
使用快捷方式。
1 | // bad |
了解更多信息在 Truth Equality and JavaScript by Angus Croll.
使用大括号包裹所有的多行代码块。
1 | // bad |
如果通过 if 和 else 使用多行代码块,把 else 放在 if 代码块关闭括号的同一行。
1 | // bad |
使用 /** ... */ 作为多行注释。包含描述、指定所有参数和返回值的类型和值。
1 | // bad |
使用 // 作为单行注释。在评论对象上面另起一行使用单行注释。在注释前插入空行。
1 | // bad |
给注释增加 FIXME 或 TODO 的前缀可以帮助其他开发者快速了解这是一个需要复查的问题,或是给需要实现的功能提供一个解决方式。这将有别于常见的注释,因为它们是可操作的。使用 FIXME -- need to figure this out 或者 TODO -- need to implement。
使用 // FIXME: 标注问题。
1 | function Calculator() { |
使用 // TODO: 标注问题的解决方式。
1 | function Calculator() { |
使用 2 个空格作为缩进。
1 | // bad |
在大括号前放一个空格。
1 | // bad |
在控制语句(if、while 等)的小括号前放一个空格。在函数调用及声明中,不在函数的参数列表前加空格。
1 | // bad |
使用空格把运算符隔开。
1 | // bad |
在文件末尾插入一个空行。
1 | // bad |
1 | // bad |
1 | // good |
在使用长方法链时进行缩进。使用前面的点 . 强调这是方法调用而不是新语句。
1 | // bad |
在块末和新语句前插入空行。
1 | // bad |
行首逗号: 不需要。
1 | // bad |
额外的行末逗号:不需要。这样做会在 IE6/7 和 IE9 怪异模式下引起问题。同样,多余的逗号在某些 ES3 的实现里会增加数组的长度。在 ES5 中已经澄清了 (source):
Edition 5 clarifies the fact that a trailing comma at the end of an ArrayInitialiser does not add to the length of the array. This is not a semantic change from Edition 3 but some implementations may have previously misinterpreted this.
1 | // bad |
使用分号。
1 | // bad |
了解更多.
字符串:
1 | // => this.reviewScore = 9; |
使用 parseInt 转换数字时总是带上类型转换的基数。
1 | var inputValue = '4'; |
如果因为某些原因 parseInt 成为你所做的事的瓶颈而需要使用位操作解决性能问题时,留个注释说清楚原因和你的目的。
1 | // good |
注: 小心使用位操作运算符。数字会被当成 64 位值,但是位操作运算符总是返回 32 位的整数(source)。位操作处理大于 32 位的整数值时还会导致意料之外的行为。讨论。最大的 32 位整数是 2,147,483,647:
1 | 2147483647 >> 0 //=> 2147483647 |
布尔:
1 | var age = 0; |
避免单字母命名。命名应具备描述性。
1 | // bad |
使用驼峰式命名对象、函数和实例。
1 | // bad |
使用帕斯卡式命名构造函数或类。
1 | // bad |
不要使用下划线前/后缀。
为什么?JavaScript 并没有私有属性或私有方法的概念。虽然使用下划线是表示「私有」的一种共识,但实际上这些属性是完全公开的,它本身就是你公共接口的一部分。这种习惯或许会导致开发者错误的认为改动它不会造成破坏或者不需要去测试。长话短说:如果你想要某处为「私有」,它必须不能是显式提出的。
1 | // bad |
不要保存 this 的引用。使用 Function#bind。
1 | // bad |
给函数命名。这在做堆栈轨迹时很有帮助。
1 | // bad |
注: IE8 及以下版本对命名函数表达式的处理有些怪异。了解更多信息到 http://kangax.github.io/nfe/。
如果你的文件导出一个类,你的文件名应该与类名完全相同。
1 | // file contents |
如果你需要存取函数时使用 getVal() 和 setVal('hello')。
1 | // bad |
如果属性是布尔值,使用 isVal() 或 hasVal()。
1 | // bad |
创建 get() 和 set() 函数是可以的,但要保持一致。
1 | function Jedi(options) { |
给对象原型分配方法,而不是使用一个新对象覆盖原型。覆盖原型将导致继承出现问题:重设原型将覆盖原有原型!
1 | function Jedi() { |
方法可以返回 this 来实现方法链式使用。
1 | // bad |
写一个自定义的 toString() 方法是可以的,但是确保它可以正常工作且不会产生副作用。
1 | function Jedi(options) { |
当给事件附加数据时(无论是 DOM 事件还是私有事件),传入一个哈希而不是原始值。这样可以让后面的贡献者增加更多数据到事件数据而无需找出并更新事件的每一个处理器。例如,不好的写法:
1 | // bad |
更好的写法:
1 | // good |
! 开始。这样确保了当一个不好的模块忘记包含最后的分号时,在合并代码到生产环境后不会产生错误。详细说明noConflict() 的方法来设置导出的模块为前一个版本并返回它。永远在模块顶部声明 'use strict';。
1 | // fancyInput/fancyInput.js |
使用 $ 作为存储 jQuery 对象的变量名前缀。
1 | // bad |
缓存 jQuery 查询。
1 | // bad |
对 DOM 查询使用层叠 $('.sidebar ul') 或 父元素 > 子元素 $('.sidebar > ul')。 jsPerf
对有作用域的 jQuery 对象查询使用 find。
1 | // bad |
Yup.
1 | function () { |
推荐阅读
工具
其它风格指南
其它风格
进一步阅读
书籍
博客
播客
这是一个使用本风格指南的组织列表。给我们发 pull request 或开一个 issue 让我们将你增加到列表上。
这份风格指南也提供了其它语言的版本:
 Brazilian Portuguese: armoucar/javascript-style-guide
Brazilian Portuguese: armoucar/javascript-style-guide Bulgarian: borislavvv/javascript
Bulgarian: borislavvv/javascript Catalan: fpmweb/javascript-style-guide
Catalan: fpmweb/javascript-style-guide Chinese(Traditional): jigsawye/javascript
Chinese(Traditional): jigsawye/javascript Chinese(Simplified): sivan/javascript
Chinese(Simplified): sivan/javascript French: nmussy/javascript-style-guide
French: nmussy/javascript-style-guide German: timofurrer/javascript-style-guide
German: timofurrer/javascript-style-guide Italian: sinkswim/javascript-style-guide
Italian: sinkswim/javascript-style-guide Japanese: mitsuruog/javacript-style-guide
Japanese: mitsuruog/javacript-style-guide Korean: tipjs/javascript-style-guide
Korean: tipjs/javascript-style-guide Polish: mjurczyk/javascript
Polish: mjurczyk/javascript Russian: uprock/javascript
Russian: uprock/javascript Spanish: paolocarrasco/javascript-style-guide
Spanish: paolocarrasco/javascript-style-guide Thai: lvarayut/javascript-style-guide
Thai: lvarayut/javascript-style-guide有一套要牢记的规则:
在 feature branch 进行工作.
why:
因为这样,所有的工作都是在一个专门的分支而不是主分支上隔离完成的。 它允许您提交多个拉请求而不会混淆。 您可以迭代,而不会污染具有潜在不稳定的未完成代码的主分支。 read more…
从 develop 拓展分支
why:
这样,您可以确保master中的代码几乎总是无问题地构建,并且可以直接用于发行版(对于某些项目而言,这可能是过度的)。
不要develop或master上push分支。 做一个拉请求。
why:
它通知团队成员已完成功能。 它还能够轻松地对代码进行同行评审,并专门讨论论坛讨论所提出的功能
在 push 你的 feature 并且提交一个 Pull Request 的时候,你应该先更新你本地 develop 分支,并且做一次交互式 rebase
why:
Rebasing将在请求的分支(
master或develop)中合并,并将您本地进行的提交应用于历史的顶端,而不创建合并提交(假设没有冲突)。 产生一个漂亮和干净的历史。read more …
在 Pull Request 前,解决潜在冲突,并且 rebasing
合并后删除本地和远程功能分支。
why:
它会使您的分支列表中的死枝混乱,确保您只将合并到(
master或develop)一次。 功能部门只能在工作进行中存在。
在 Pull Request 前,确保你的 feature 分支可以构建成功并且通过所有测试(包括代码风格)
使用 .gitignore.
保护你的 develop 和 master 分支 .
在 package.json 的 engines 中配置你所用的 node 版本
1 | { "engines" : { "node" : ">=0.10.3 <0.12" } } |
why:
让他人知道你所用的 node.js 版本 read more…
另外,使用 nvm 并在您的项目根目录中创建一个 .nvmrc。 不要忘了在文档中提及它
why:
所有使用
nvm的人都可以简单的使用nvm use去选择合适的 node 版本 read more…
您还可以使用 preinstall 脚本来检查节点和npm版本
why:
当使用新的版本node时,有些项目可能会失败
使用 Docker images,只要它不会使事情更复杂
why:
它可以在整个工作流程中为您提供一致的环境。 没有太多的需要解决libs,依赖或配置。read more…
使用本地模块,而不是使用全局安装的模块
why:
让你与你的同事分享你的工具,而不是期望他们在他们的系统上。
在使用包之前,请检查它的GitHub。 查找开放问题的数量,每日下载次数和贡献者数量以及上次更新软件包的日期。
npm ls --depth=0. read more…depcheck. read more…npm-stat. read more…npm view async. read more…npm outdated. read more…npm@5 或者更高版本上使用 package-lock.jsonnpm, 当安装新的依赖时使用 --save --save-exact 并且发布前创建一个 npm-shrinkwrap.jsonYarn 并且确保在 README.md 中提及. 你的 lock 文件和 package.json 在每次依赖关系更新后应该具有相同的版本。*.test.js 或 *.spec.js 命名约定将测试文件放在测试模块旁边develop 的 pull requests 前进行测试Bad
1 | . |
Good
1 | . |
./config 文件夹。 配置文件中使用的值由环境变量提供。./scripts 文件夹中。 这包括用于数据库同步,构建和捆绑等的 bash 和 node 脚本。./build 文件夹中。 将 build/ 添加到 .gitignore。PascalCase(帕斯卡拼写法) 和 camelCase(驼式命名法) 作为文件名和目录名。 使用 PascalCase 仅用于组件名。CheckBox/index.js 应该有 CheckBox 组件, 但 不是 CheckBox/CheckBox.js 或者 checkbox/CheckBox.js,这些是冗余的。index.js 默认导出的名称相匹配。stage-1 和更高版本的JavaScript(现代)语法。 对于旧项目,与现有语法保持一致,除非您打算使项目现代化。.eslintignore 从代码样式检查中排除文件或文件夹。eslint 禁用注释,然后再执行 Pull Request 。//TODO: 评论来提醒自己和他人关于未完成的工作。遵循资源导向的设计。 这有三个主要因素:resources, collection, 和 URLs.
/users 一组用户(复数名词)。/users/id 具有特定用户信息的资源。GET /translate?text=Hallo
camelCase 来保持一致性。table_name 作为资源名称。 与资源属性相同,它们不应与您的列名称相同。Only use nouns in your resource URLs, avoid endpoints like /addNewUser or /updateUser . Also avoid sending resource operations as a parameter. Instead explain the functionalities using HTTP methods:
Sub resources are used to link one resource with another, so use sub resources to represent the relation.
An API is supposed to be an interface for developers and this is a natural way to make resources explorable.
If there is a relation between resources like employee to a company, use id in the URL:
/schools/2/students Should get the list of all students from school 2/schools/2/students/31 Should get the details of student 31, which belongs to school 2/schools/2/students/31 Should delete student 31, which belongs to school 2/schools/2/students/31 Should update info of student 31, Use PUT on resource-URL only, not collection/schools Should create a new school and return the details of the new school created. Use POST on collection-URLsWhen your APIs are public for other third parties, upgrading the APIs with some breaking change would also lead to breaking the existing products or services using your APIs. Using versions in your URL can prevent that from happening:http://api.domain.com/v1/schools/3/students
Response messages must be self descriptive. A good error message response might look something like this:1
2
3
4
5{
"code": 1234,
"message" : "Something bad happened",
"description" : "More details"
}
or for validation errors:
1 | { |
Note: Keep security exception messages as generic as possible. For instance, Instead of saying ‘incorrect password’, you can reply back saying ‘invalid username or password’ so that we don’t unknowingly inform user that username was indeed correct and only password was incorrect.
200 OK This HTTP response represents success for GET, PUT or POST requests.201 Created This status code should be returned whenever a new instance is created. E.g on creating a new instance, using POST method, should always return 201 status code.204 No Content represents the request was successfully processed, but has not returned any content. DELETE can be a good example of this. If there is any error, then the response code would be not be of 2xx Success Category but around 4xx Client Error category.400 Bad Request indicates that the request by the client was not processed, as the server could not understand what the client is asking for.401 Unauthorized indicates that the request lacks valid credentials needed to access the needed resources, and the client should re-request with the required credentials.403 Forbidden indicates that the request is valid and the client is authenticated, but the client is not allowed access the page or resource for any reason.404 Not Found indicates that the requested resource was not found.406 Not Acceptable A response matching the list of acceptable values defined in Accept-Charset and Accept-Language headers cannot be served.410 Gone indicates that the requested resource is no longer available and has been intentionally and permanently moved.500 Internal Server Error indicates that the request is valid, but the server could not fulfill it due to some unexpected condition.503 Service Unavailable indicates that the server is down or unavailable to receive and process the request. Mostly if the server is undergoing maintenance or facing a temporary overload.The amount of data the resource exposes should also be taken into account. The API consumer doesn’t always need the full representation of a resource.Use a fields query parameter that takes a comma separated list of fields to include:
1 | GET /student?fields=id,name,age,class |
Pagination, filtering and sorting don’t need to be supported by default for all resources. Document those resources that offer filtering and sorting.
To secure your web API authentication, all authentications should use SSL. OAuth2 requires the authorization server and access token credentials to use TLS.
Switching between HTTP and HTTPS introduces security weaknesses and best practice is to use TLS by default for all communication. Throw an error for non-secure access to API URLs.
If your API is public or have high number of users, any client may be able to call your API thousands of times per hour. You should consider implementing rate limit early on.
It’s difficult to perform most attacks if the allowed values are limited.
Validate required fields, field types (e.g. string, integer, boolean, etc), and format requirements. Return 400 Bad Request with details about any errors from bad or missing data.
Escape parameters that will become part of the SQL statement to protect from SQL injection attacks
As also mentioned before, don’t expose your database scheme when naming your resources and defining your responses
Attackers can tamper with any part of an HTTP request, including the URL, query string,
The server should never assume the Content-Type. A lack of Content-Type header or an unexpected Content-Type header should result in the server rejecting the content with a 406 Not Acceptable response.
A key concern with JSON encoders is preventing arbitrary JavaScript remote code execution within the browser or node.js, on the server. Use a JSON serialiser to entered data to prevent the execution of user input on the browser/server.
API Reference section in README.md template for API.For each endpoint explain:
URL Params If URL Params exist, specify them in accordance with name mentioned in URL section
1 | Required: id=[integer] |
If the request type is POST, provide a working examples. URL Params rules apply here too. Separate the section into Optional and Required.
Success Response, What should be the status code and is there any return data? This is useful when people need to know what their callbacks should expect!
1 | Code: 200 |
Error Response, Most endpoints have many ways to fail. From unauthorised access, to wrongful parameters etc. All of those should be listed here. It might seem repetitive, but it helps prevent assumptions from being made. For example
1 | { |
There are lots of open source tools for good documentation such as API Blueprint and Swagger.
Make sure you use resources that you have the rights to use. If you use libraries, remember to look for MIT, Apache or BSD but if you modify them, then take a look into licence details. Copyrighted images and videos may cause legal problems.
Sources:
RisingStack Engineering,
Mozilla Developer Network,
Heroku Dev Center,
Airbnb/javascript
Atlassian Git tutorials
假设你现在基于远程分支”origin”,创建一个叫”mywork”的分支。
1 | $ git checkout -b mywork origin |
现在我们在这个分支做一些修改,然后生成两个提交(commit).
1 | $ vi file.txt |
但是与此同时,有些人也在”origin”分支上做了一些修改并且做了提交了. 这就意味着”origin”和”mywork”这两个分支各自”前进”了,它们之间”分叉”了。
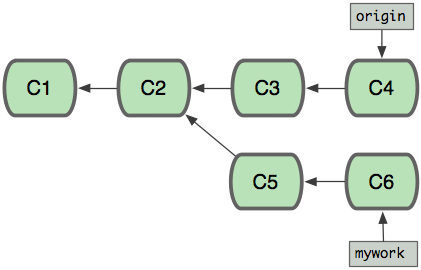
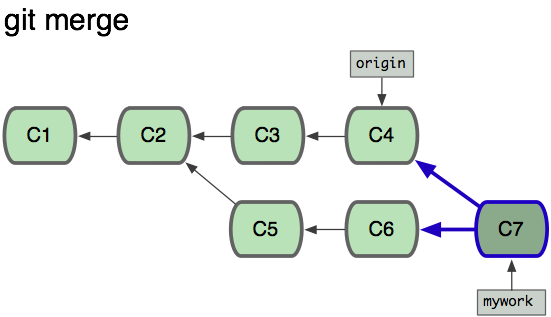
在这里,你可以用”pull”命令把”origin”分支上的修改拉下来并且和你的修改合并; 结果看起来就像一个新的”合并的提交”(merge commit):
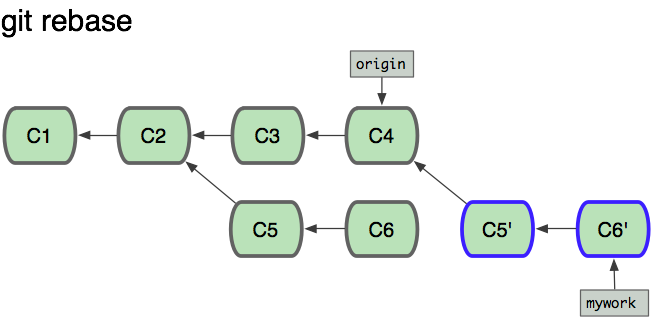
但是,如果你想让”mywork”分支历史看起来像没有经过任何合并一样,你也许可以用 git rebase:
1 | $ git checkout mywork |
这些命令会把你的”mywork”分支里的每个提交(commit)取消掉,并且把它们临时 保存为补丁(patch)(这些补丁放到”.git/rebase”目录中),然后把”mywork”分支更新 到最新的”origin”分支,最后把保存的这些补丁应用到”mywork”分支上。
当’mywork’分支更新之后,它会指向这些新创建的提交(commit),而那些老的提交会被丢弃。 如果运行垃圾收集命令(pruning garbage collection), 这些被丢弃的提交就会删除. (请查看 git gc)
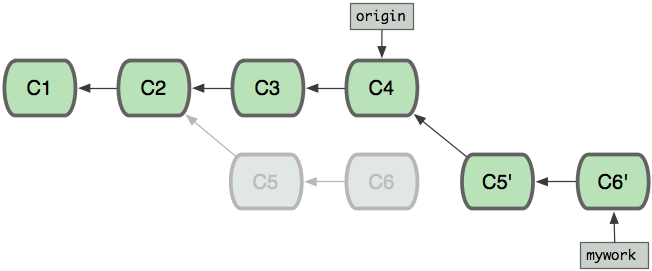
现在我们可以看一下用合并(merge)和用rebase所产生的历史的区别:
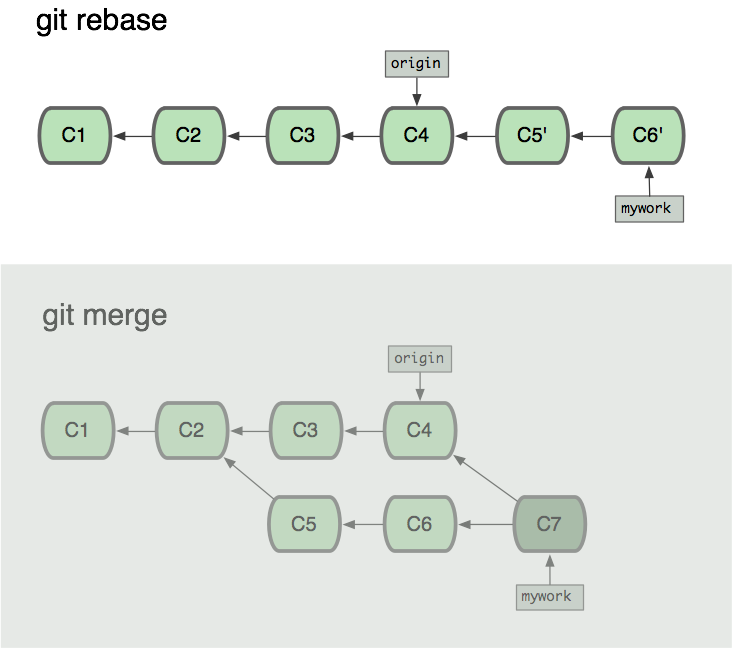
在rebase的过程中,也许会出现冲突(conflict). 在这种情况,Git会停止rebase并会让你去解决 冲突;在解决完冲突后,用”git-add”命令去更新这些内容的索引(index), 然后,你无需执行 git-commit,只要执行:
1 | $ git rebase --continue |
这样git会继续应用(apply)余下的补丁。
在任何时候,你可以用–abort参数来终止rebase的行动,并且”mywork” 分支会回到rebase开始前的状态。1
$ git rebase --abort
Document 对象,并开始解析Web页面,解析 HTML 元素和它们的文本内容后添加 Element 对象和 Text 节点套文档中。这个阶段 document.readyState 属性的值是 "loading"。HTML 解释器遇到了没有 async 和 defer 属性的 <script> 元素时,他把这些元素添加到文档中,并且同步执行。在脚本下载(如果需要)和执行时解释器会暂停。这样脚本就可以用 document.write() 来把文本插入到输入流中。async 属性(如果 <script> 标签同时有 async 和 defer 属性,会遵从 async 并忽略 defer)的 <script> 元素时,它开始下载脚本文本,并继续解析文档。脚本会在它下载完成后尽快执行。禁止使用 document.write() 方法。document.readyState 属性变成 "interactive"。defer 属性的脚本,会按它们在文档里出现的顺序执行。异步脚本可能也会在这个时间执行。延迟脚本能访问完整的文档树,禁止使用 document.write() 方法。Document 对象上触发 DOMContentLoaded 事件。这标志着 程序执行从同步脚本执行阶段转换到了异步事件驱动阶段 但是,这时可能还有异步脚本没有执行完成。document.readyState 属性改变为 complete ,Web浏览器触发 window 对象上的 load 事件。| 事件名称 | 描述 |
|---|---|
readystatechange |
文档还在加载:loading, 文档解析完成:interactive, 文档完全加载完成:complete |
DOMContentLoaded |
程序执行从同步脚本执行阶段转换到了异步事件驱动阶段 |
load |
所有内容完全载入,所有异步脚本完全载入和执行 |
1 | document.addEventListener('DOMContentLoaded', function(){ |
运行结果:1
2
3
4interactive
DOMContentLoaded
complete
load

Nothing to say
Front-End Development Engineer
